
It was noted that the universal switch block appears to be more limiting than originally made out to be; if the routing requirements include fanout at a switch block, there may be some signals which are blocked. The figure below illustrates this; note that an east-west route cannot be added to either of the switch blocks at the bottom of the diagram. A quick solution could be to route the east-west connection through one of the switch points at the bottom of the block. Another solution would be to handle fanout at the signal source itself; this would mean the global router must allocate extra channels to handle the fanout along the entire length of the route.
As well, although the set of route requests for any single switch box may be satisfiable with universal switch blocks, it is not clear that a the the routes through a collection of universal switch boxes can all be satisfied simultaneously.
The goal of LUT mapping is to assign gates in a netlist to LUTs on an FPGA optimally, given a goal of area or delay. This is similar to technology mapping for traditional designs. However, the libraries involved can also quite large; without special consideration for input permutability, there are 2^(2^K) possible ``gates'' in such a library, where K is the number of LUT inputs for the FPGA. Accounting for input permutations, the library size is still significant; for K=4, there are 9014 functionally different LUT configurations.
A simplification which is of great help is that a K-LUT can implement any function on K inputs; thus we need not concern ourselves with the function of the gates which are mapped to a LUT as long as the input constraints are met.

In general, the mapping problem is NP-hard; however, there are a number of simplifications which make the problem tractable. If we have a fanout-free network, we can solve the mapping problem optimally given a decomposition of the network; that is, the solution obtained can be demonstrated to be optimal among all the possible mappings for the given decomposition. We will see shortly an example of how decomposition affects the mapping process.
The Chortle algorithm [1] has been shown give optimal delay or area for fanout free logic for small LUT sizes (K<=5); what makes Chortle interesting is that the algorithm builds the decomposition at the same time it constructs the mapping. Thus, the mapping is optimal over all decompositions for fanout-free networks.
FlowMap [2] gives an optimal delay for any network, even ones with fanout. However, the algorithm is affected by the decomposition chosen.
The DF-map algorithm gives an area-optimal mapping for networks which are ``duplication free''; i.e. no nodes in the network are allowed to be replicated as part of the mapping process. As we will see, node duplication can be used to aid the mapping process. This algorithm is also dependent on the decomposition of the network.

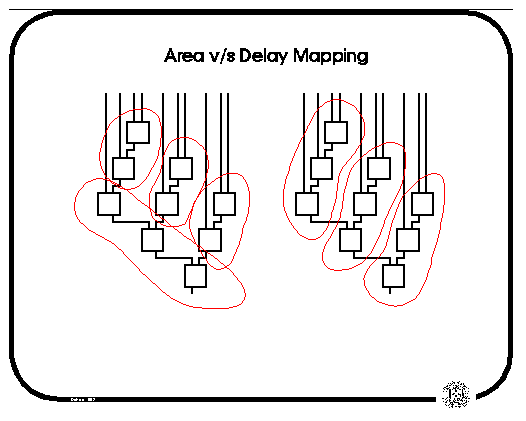
We note that delay and area optimization are somewhat orthogonal concepts; often we obtain one at the expense of the other. In the slide below, we see two possible mappings for LUTs where K=4. The mapping on the left obtains a delay of 2 LUT delays from inputs to output, while the mapping on the right gives 3 LUT delays through the network. However, the mapping on the right uses only 3 LUTs, while the mapping on the left uses 4 LUTs.
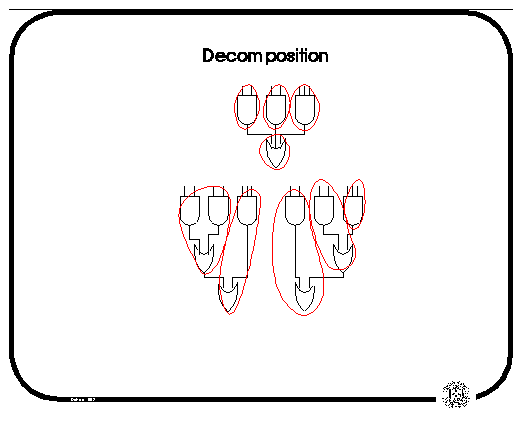
As noted earlier, the decomposition of the network into gates can also affect the mapping. In the slide below, note that the topmost network is mapped naively into 4 LUTs (again K=4). The decompositions at the bottom show how different (smaller) mappings can be found, depending on how the OR gate is decomposed; the decomposition on the right does not allow a mapping into 2 LUTs.
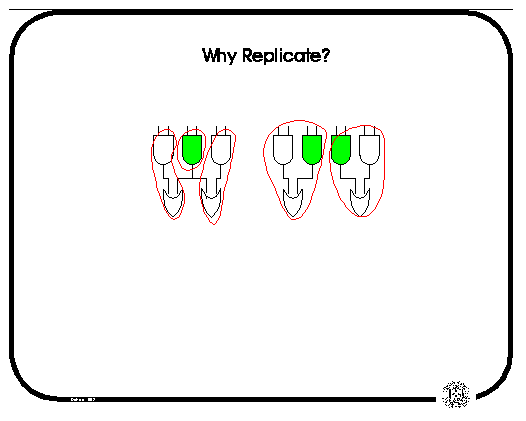
Node replication in the network can also simplify the mapping; the network on the left cannot be mapped into fewer than 3 4-input LUTs; whereas the network on the right can fit in 2 LUTs.
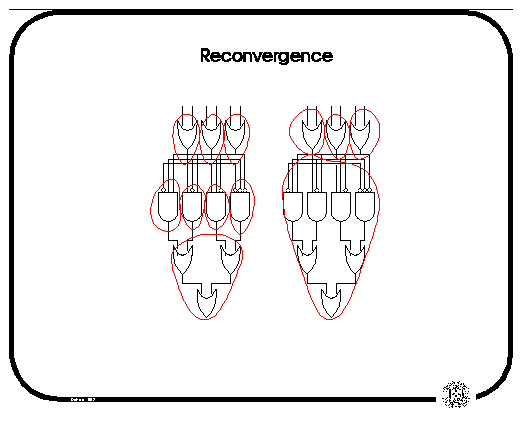
We must also take advantage of reconvergence in the network; in the figure below, the mapping on the left does not look far back enough (towards the inputs) to find the superior mapping indicated on the right.
Dynamic programming is used in both Chortle and FlowMap. The target network is traversed from inputs to outputs (topological order); for any node, the optimal (local) solution can be found by combining the solutions at nodes which appear above the node being considered (i.e. closer to the inputs). Since these nodes have already been evaluated, this task is greatly simplified.

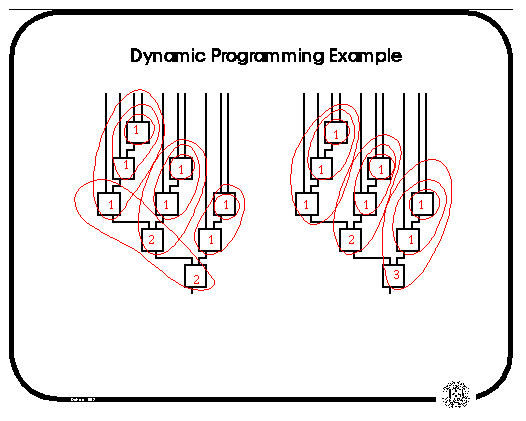
In the example on the left below, the mapping goal is to minimize delay. We iterate through the nodes in order from the inputs. At each node, we can consider a LUT which implements that node; the delay for such an implementation is then one plus the maximum delay over all nodes which feed the LUT under consideration. The minimum delay for the node is thus the minimum delay over all LUT implementations of that node. In the diagram on the left, each loop represents the minimum depth LUT which implements each node, with the delay of the LUT written inside the loop. The figure on the right shows the corresponding mapping for area; the value of a node in this case is thus the sum of the values of the nodes which fanin to the LUT plus 1.
This problem is suited for dynamic programming, since a local decision (LUT mapping) does not affect the solution obtained for the subproblems (i.e. nodes already visited). Also note that this is optimal for fanout free networks.
Chortle gives a modification to this idea; at each node, the LUTs which fanin to that node are packed into bins, representing the decomposition for that node; these LUTs may utilize fewer than K inputs. Each bin has a capacity of K inputs; each LUT contributes the number of inputs to that LUT to the capacity of the bin in which it is placed; thus each bin represents a realizable LUT in the target FPGA. These bins are then greedily linked together to more completely utilize any remaining free inputs on the bins.

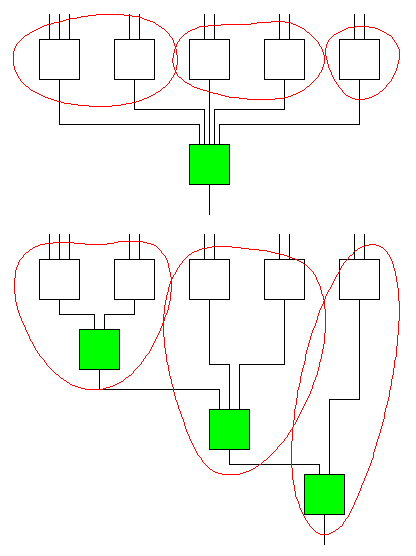
The following is an example from [1]; K=5 for this example. The green node is the node currently being decomposed. The top figure shows the initial bin packing, while the bottom shows the bin linking. Note how unused inputs on the bins are used to chain together the LUTs, rather than using an additional LUT for this task.
FlowMap uses dynamic programming as well; initially, the network is decomposed into 2-input gates. At each node, we compute a minimum-height cut of the network which cuts no more than K nets; this is called a K-feasible cut, since we can implement all of the logic on one side of the cut with a K-input LUT.

The main idea in FlowMap is that a min-cut, max-flow algorithm can be used to quickly find K-feasible cuts in the network. The sources of flow are the primary inputs to the network, and the sink is the node currently being considered for mapping. Note that the depth of a node must either be the same as the maximum depth of all its predecessors, or this value plus 1. Thus, we can do the following:

Area minimization can be accounted for during execution of the FlowMap algorithm. When we find a min-cut, we partition the network along this cut. Any node not reachable from the primary inputs (by depth-first search) can be mapped to a single LUT (the one which implements the node currently being mapped).
After obtaining a depth-optimal LUT mapping, we clean up the solution in a postprocessing stage. LUTs may be combined with predecessors; since we found min-cuts of the network rather than K-feasible cuts, the LUTs obtained in the mapping may not fully utilize their K inputs. Thus we can check if we can cover a LUT and some of its predecessors with a supernode which is implementable with a K-LUT. A related optimization is to attempt a gate decomposition; consider a LUT in the mapped network. Some subset of the LUTs which fanin into this LUT might have fewer than K distinct inputs among them; in this case, it is possible that the LUT under consideration could be decomposed and these fanin LUTs combined into a single LUT.

We introduce the concept of a maximum fanout-free cone (MFFC) in a network. The MFFC for a node n is defined as the maximum set of nodes where each node in the MFFC either
The following diagram shows the MFFCs for some of the nodes in a network (in green); these MFFCs form a partition of the network.
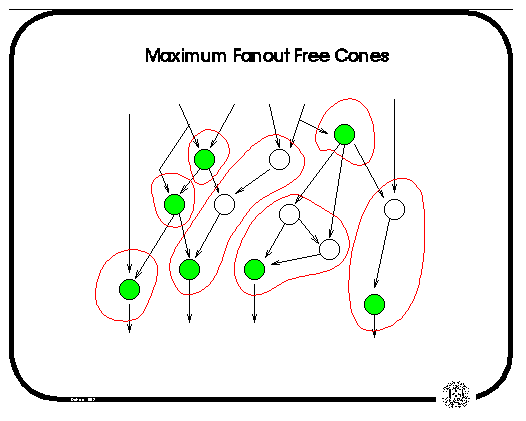
A partitioning of a network into MFFCs can be used to minimize the area (number of LUTs) used by the network; this is the idea behind the DF-map algorithm. If we are not allowed to duplicate nodes, then each MFFC must be mapped separately. The nodes in a MFFC are traversed starting from the nodes closest to the primary inputs of the network; note that the MFFC for each of these nodes is completely contained in a single partition of the network. Dynamic programming is used to find the minimum cost of a node; the (area) cost of a LUT which implements a node is 1 plus the sum of the costs of the nodes which fanin to the LUT.

Note that FlowMap optimizes for delay; every node appears as close to the inputs as possible. Sometimes this is not desirable; nodes which are not on the critical path of the circuit have some slack, and the depth of these nodes can be increased without affecting the operation of the circuit. This suggests the algorithm used in FlowMap-r. Here, the circuit is mapped as usual with FlowMap, except nodes which do not appear on the critical path. These are mapped with DF-map in order to optimize the area; since these nodes are not critical, we can tolerate an increase in delay for these nodes.

Often a technique which is used is the application of technology independent optimization before LUT mapping is performed. This might not be very beneficial when we consider that Chortle derives its own decomposition of the network; the decomposition performed in a technology independent optimizer may be wasted effort.
To illustrate this, the following two slides show the results obtained when SIS is used as a technology independent optimization step before LUT mapping with Chortle. Four cases are shown; SIS can be used to optimize for depth or area, and likewise Chortle can target either goal. The first slide shows the result for a single benchmark circuit, while the second shows the averages for a set of benchmarks. Note that the goal used for Chortle seems to have a larger effect on the final results than the goal chosen for SIS.



$Id: scribe19.html,v 1.1 1997/04/07 09:28:02 pchong Exp pchong $