**CIS 192 Homework 3: Scripting and Testing**
**Due Mon February 20, 2023 11:59 pm EST**
(#) Learning objectives
- Familiarization with first party modules
- `argparse`
- `json`
- `unittest`
- Familiarization with third party modules
- `requests`
- Practice writing unit tests
(#) Starter files
- [reddit.py](hw3/reddit.py)
- [test_reddit.py](hw3/test_reddit.py)
(#) Python as a scripting language
As we have seen so far, Python is a high-level and interpreted language with clear and concise syntax. These attributes make it a good choice for a number of tasks, such as [scripting](https://en.wikipedia.org/wiki/Scripting_language).
A script is a short, relatively simple program which is executed from the command line with the goal of consolidating multiple complex Terminal commands into a single simpler command. A few examples of scripting languages include Python, Bash, and PowerShell.
In this homework, you will build a command line utility that manipulates JSON data and presents that data in the Terminal. For those of you who have never used JSON, it uses the JavaScript Object Notation to encode data as a series of keys and values. If you are unfamiliar with JSON, [click here](https://www.w3schools.com/js/js_json_intro.asp) to learn more.
In addition to manipulating JSON data, you will also practice writing unit tests for your script to ensure correct behavior.
(##) Setup
This is our first homework assignment that uses modules, including a 3rd party module that does not come installed by default. You can install `requests` like we did in lecture by executing `python3 -m pip install requests`:
~~~~~~~~ bash
# the output of your terminal may look something like this
$ python3 -m pip install requests
Collecting requests
Using cached requests-2.24.0-py2.py3-none-any.whl (61 kB)
Collecting urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1
Using cached urllib3-1.25.10-py2.py3-none-any.whl (127 kB)
Requirement already satisfied: certifi>=2017.4.17 in ...
Collecting chardet<4,>=3.0.2
Using cached chardet-3.0.4-py2.py3-none-any.whl (133 kB)
Collecting idna<3,>=2.5
Using cached idna-2.10-py2.py3-none-any.whl (58 kB)
Installing collected packages: urllib3, chardet, idna, requests
Successfully installed chardet-3.0.4 idna-2.10 requests-2.24.0 urllib3-1.25.10
~~~~~~~~
Further documentation for using the `requests` module can be found [here](https://requests.readthedocs.io/en/master/).
(#) Redditing from the terminal
With web browsers these days tracking your every move, and with pesky advisers or managers peeking over your shoulder to see what's on your computer screen, sometimes you just want to do some Reddit browsing from the safety of your inconspicuous terminal. This script `reddit.py` will do exactly that, allowing you to pull posts from your subreddit of choice and display them in your terminal window.
Running any script or command with the `-h` (meaning "help") flag provides the user with a small help page for running that script/command, including possible options and arguments to change the execution. See a sample `python3 reddit.py -h` output below:
~~~~~~~~~~~~~~~~~~~~~~shell linenumbers
$ python3 reddit.py -h
usage: reddit.py [-h] [-n N] [-o {score,title}] [-t T] url
Pulls posts from subreddit and displays them in terminal
positional arguments:
url the URL or subreddit to visit
optional arguments:
-h, --help show this help message and exit
-n N number of posts to display (default: 10)
-o {score,title} field to sort posts by (default: score)
-t T truncate title to specified length (default: 60)
~~~~~~~~~~~~~~~~~~~~~~
!!!
When you run `python3 reddit.py -h` you may have a slightly different output depending on what help text you write.
- The `-n` flag specifies the number of posts to display. By default, this is 10.
- The `-o` flag specifies the Reddit post attribute to use for sorting the posts. By default this should be score. Note, if the parameter is score, then the posts should be ordered in descending order. Otherwise, the posts should be ranked in ascending order.
- The `-t` flag specifies the maximum length for the posts' titles. Titles longer than this value should be truncated. The default value is 60.
(##) Example Usage
~~~~~~~~~~~~~~~~~~~~~~~~~~ bash
# view the r/python subreddit with default parameters
$ python3 reddit.py python
0. Mypy 1.0 Released (score: 432)
https://mypy-lang.blogspot.com/2023/02/mypy-10-released.html
1. My first end to end python project. (score: 278)
https://www.reddit.com/r/Python/comments/10v36mr/my_first_end_to_end_python_project/
2. Gracy helps you handle failures, logging, retries, throttlin (score: 105)
https://www.reddit.com/r/Python/comments/10w0ykx/gracy_helps_you_handle_failures_logging_retries/
3. Building a real-time application using Python and WebSockets (score: 78)
https://www.reddit.com/r/Python/comments/10v99mp/building_a_realtime_application_using_python_and/
4. Lessons learned from 7 years of using mypy (score: 77)
https://www.reddit.com/r/Python/comments/10vnuxf/lessons_learned_from_7_years_of_using_mypy/
5. I wrote my first unit test today! (score: 49)
https://www.reddit.com/r/Python/comments/10vufhi/i_wrote_my_first_unit_test_today/
6. Build a Wordle Clone With Python and Rich – Real Python (score: 10)
https://realpython.com/python-wordle-clone/
7. txtai 5.3 released: open-source semantic search (score: 9)
https://github.com/neuml/txtai
8. Deploy your Pynecone app on Huggingface Spaces! (score: 7)
https://www.reddit.com/r/Python/comments/10vytoq/deploy_your_pynecone_app_on_huggingface_spaces/
9. Open Source Pricing and Billing Engine Built In Python (score: 6)
https://www.reddit.com/r/Python/comments/10w8pvc/open_source_pricing_and_billing_engine_built_in/
# view the top 5 r/nba subreddit posts
$ python3 reddit.py nba -n 5
0. [Highlight] Dame defies all logic as he drills the standing (score: 19354)
https://streamable.com/3w1jcc
1. Vardon: Several people close to James described that loss in (score: 5658)
https://www.reddit.com/r/nba/comments/10w6gdb/vardon_several_people_close_to_james_described/
2. Cam Thomas explodes AGAIN vs the Clippers with a Career High (score: 5278)
https://www.reddit.com/r/nba/comments/10vqjuc/cam_thomas_explodes_again_vs_the_clippers_with_a/
3. Klay Thompson checks out with 42 points on 12 threes! (score: 4543)
https://www.reddit.com/r/nba/comments/10vt8xk/klay_thompson_checks_out_with_42_points_on_12/
4. Remember the apology by Kyrie about the video he posted? Som (score: 2672)
https://www.reddit.com/r/nba/comments/10w8upt/remember_the_apology_by_kyrie_about_the_video_he/
# view top 2 r/aww subreddit posts sorted by title with shortened titles
$ python3 reddit.py aww -n 2 -o title -t 30
0. (OC) This Kitten I found on va (score: 1195)
https://i.redd.it/0542ikr81rga1.jpg
1. A friend of mine reached out t (score: 9113)
https://v.redd.it/6hfrtjixcoga1
# view top 2 r/philadelphia subreddit posts sorted by score
$ python3 reddit.py philadelphia -n 2 -o score
0. Stop parking on corners 🗣️ (score: 1458)
https://v.redd.it/4ibmsta0pnga1
1. Recent pics around Center City (score: 227)
https://www.reddit.com/gallery/10w58lr
~~~~~~~~~~~~~~~~~~~~~~~~~~
!!!
Since we're pulling data from an active website, the posts will likely have changed when you run these commands.
(#) Implementation details
(##) `reddit.py`
You will implement the following functions:
- `build_parser()`: returns an [ArgumentParser](https://docs.python.org/3/library/argparse.html#argparse.ArgumentParser) instance with the defined parameters above.
- `load_reddit_data()`: Loads reddit data from a given URL into a list of dicts.
- `format_reddit_data()`: Sorts and formats the list of dicts from `load_reddit_data()`
- `print_reddit_data()`: Prints the given list of reddit data in the specified string format
Further details on the function behvaior can be found in the docstrings provided in the starter file.
!!! Tip
For code style this assignment, we will be performing a close read of `format_reddit_data()` **and** the unit test associated with it, `test_format_reddit_data()`.
(##) HTTP - Some Background
[Hypertext Transfer Protocol](https://developer.mozilla.org/en-US/docs/Web/HTTP) is the protocol through which client computers and servers communicate. Traditionally, a client (e.g. you on your computer) will send an HTTP request to some server (e.g. Reddit) by clicking on a link. The server will give an HTTP response back to the client, which will either contain the content that the client requested (e.g. the Reddit homepage) or an error explaining that something went wrong. There are a few different kinds of HTTP requests, but you only need to worry about [GET requests](https://developer.mozilla.org/en-US/docs/Web/HTTP/Methods/GET).
However, a user surfing the web isn't the only way that HTTP requests can be sent. Programs can also send HTTP requests to retrieve information from a server to use as a part of its execution. This is where JSON comes into play--JSON is a way for servers to encode information that a program might request. The simple key-value representation makes it easy for programmers to dissect and use the information coming from the request. We will explain how to send a GET request for JSON data in the following section.
For the sake of simplicity, you do not need to handle HTTP errors, and you only need to worry about sending HTTP [GET requests](https://developer.mozilla.org/en-US/docs/Web/HTTP/Methods/GET).
(##) JSON and `requests`
Reddit provides a [JSON](https://www.json.org/json-en.html) feed for each subreddit which can be accessed by adding `.json` to the end of any subreddit url. We will fetch JSON data via the `requests` module.
The HTTP request has two components: the request line (which you don't need to worry about) and the headers. The headers are a series of key-value pairs with information that the server should know before sending the its response.
In order to send an HTTP GET request, you will be using the [`requests.get()`](https://requests.readthedocs.io/en/master/api/#requests.get) method, which requires a URL argument and accepts an optional argument describing its request headers.
!!! WARNING Respecting web scraping rules
The Reddit admins require that all requests sent via web scraper include the request header `user-agent` so they can keep track of the requests they receive. It is imperative that you include this header in your request, and **including this header is part of the grading rubric.**
You can see an example of how to specify the headers for an HTTP request and then make a GET request below:
~~~~~~~~~~~~~~~ python
headers = {
"user-agent": "CIS 1920 Spring 2023 HW3 by [insert your email here]"
}
response = requests.get("https://www.reddit.com/r/python/.json", headers=headers)
~~~~~~~~~~~~~~~
where `headers` is a Python dict, and `response` is a Python string.
We can then access the JSON data from the response in the form of a Python dict by calling the `response.json()` method:
~~~~~~~~~~~~~~~ python
print(response.json())
{'kind': 'Listing', 'data': {'modhash': '', 'dist': 27, 'children': [{'kind': 't3', 'data': {'approved_at_utc': None, 'subreddit': 'Python', ...
~~~~~~~~~~~~~~~
The output from `response.json()` can be treated like a normal Python dict. You should use this dict to retrieve the Reddit data to display as output.
The resulting dict may be a bit overwhelming to look at, so to make viewing easier you can pretty print it using:
~~~~~~~~~~~~~~~ python
print(json.dumps(response.json(), indent=4))
{
"kind": "Listing",
"data": {
"modhash": "",
"dist": 27,
"children": [
{
"kind": "t3",
"data": {
"approved_at_utc": null,
"subreddit": "Python",
...
~~~~~~~~~~~~~~~
(##) `test_reddit.py`
For this homework assignment, you will write your own unit tests to check the correctness of your function implementation. We've provided function stubs in `test_reddit.py` for you to do so, with the exception of `print_reddit_data()`, which you do not have to test. You can run your unit tests like we did in lecture by executing `python3 test_reddit.py`:
~~~~~~~~~~ bash
$ python3 test_reddit.py
usage: test_reddit.py [-h] [-n N] [-o {score,title}] [-t T] url
Pulls top posts from subreddit and displays them in terminal
positional arguments:
url the URL or subreddit to visit
optional arguments:
-h, --help show this help message and exit
-n N number of posts to display (default: 10)
-o {score,title} field to sort articles by (default: score)
-t T truncate title to specified length (default: 60)
...
----------------------------------------------------------------------
Ran 3 tests in 0.003s
OK
~~~~~~~~~~
You are free to write whatever test cases you'd like in order to ensure proper functionality of your implementation. Most importantly, we will be checking whether your unit tests have adequate **code coverage,** which is the percentage of the lines of code your test cases cover out of all the lines of code. You will receive full credit if your unit tests cover **at least 80% of your code**.
!!!
Note that code coverage considers which lines of code are run during a test, not whether each individual line of code has a test case associated with it.
For example, this simple unit test we wrote during lecture for `fib_generator()` has 100% code coverage:
~~~~~~~~~~~~~~~ python
# this example function is a generator which creates an iterable Fibonacci sequence
def fib_generator(max_iter=5):
"""Generate the fibonacci sequence for the specified iterations."""
prev, curr = 0, 1
for _ in range(max_iter):
yield curr
prev, curr = curr, prev + curr
# this is an example test of the above Fibonacci generator function
def test_fib_generator(self):
"""Tests fib_generator()""" # triple quotes is a description of the test
expected_five = [1,1,2,3,5]
# tests default max_iter
actual_five = list(fib_generator())
self.assertEqual(actual_five, expected_five) # assertEqual compares 2 values, just like JUnit
~~~~~~~~~~~~~~~
We have already provided a test case for `build_parser()` in the starter file as an additional example.
To check your unit test coverage, simply submit `test_reddit.py` and `reddit.py` to Gradescope and you will see an output like the following.
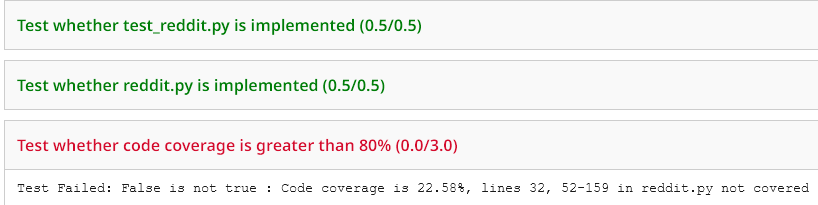
Don't worry too much about the code coverage threshold -- if you implement all of the test stubs with one test per function, your code coverage should be more than enough. The autograder in Gradescope will also tell you which lines of code are not covered if you do not meet the threshold, which will help you adjust your test cases.
Outside of the unit test coverage, we will check the functionality of your implementation by running the four commands shown above in the "Example Usage" section.
**Since the subreddits are live and post scores can change in real time, we do not expect the outputs to match exactly.**
!!!
When you submit to Gradescope, the four commands will not be autograded, but you will see the output we will use to manually check the functionality of your script, so you can verify the output is similar:
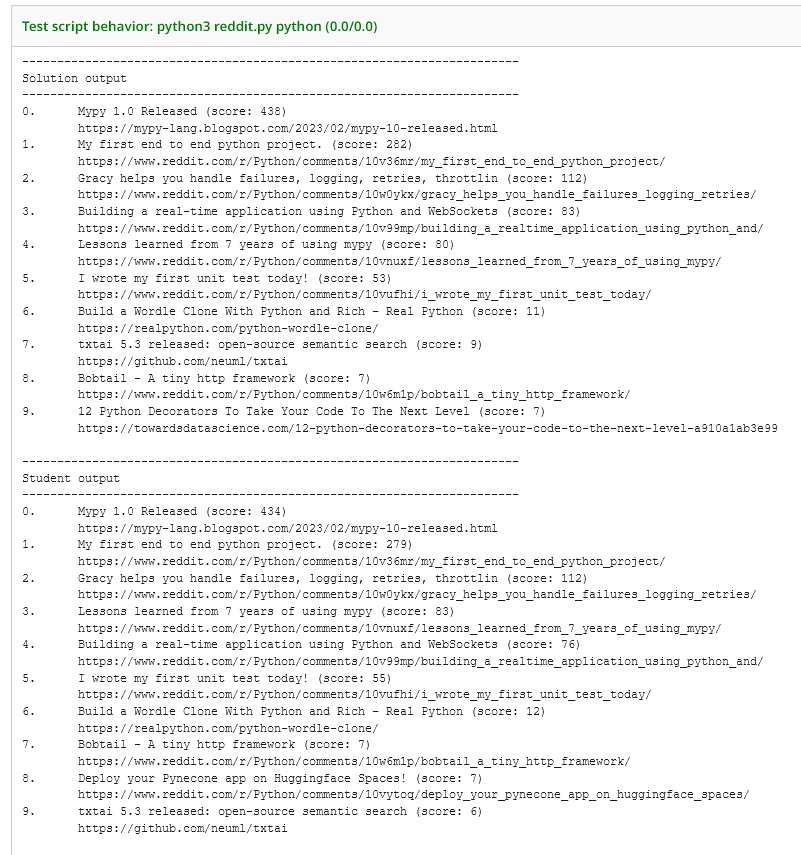
(##) Other Requirements
!!! WARNING
No libraries outside of `argparse`, `json`, `requests`, and `unittest` may be imported for this homework.
(#) Rubric
| Section | Points |
|---------|--------|
Name, PennKey, and hours filled in | 0.5
All functions in `reddit.py` are implemented | 0.5
All test cases in `test_reddit.py` are implemented | 0.5
`requests` header correctly populated | 0.5
Test cases achieve at least 80% code coverage | 3
`python3 reddit.py python` correctness | 1
`python3 reddit.py nba -n 5` correctness| 1
`python3 reddit.py aww -n 2 -o title -t 30` correctness | 1
`python3 reddit.py philadelphia -n 2 -o score` correctness | 1
`format_reddit_data()` and
`test_format_reddit_data()` code style | 1
**Total** | 10
(#) Submission
You will upload both your `reddit.py` and `test_reddit.py` code to [**Gradescope**](https://www.gradescope.com/courses/477992) for submission -- **be sure to upload both files at the same time!** We encourage you to work iteratively, implementing functions one at a time to verify their correctness before moving on to the next function. To facilitate this, you are welcome
to submit to Gradescope to verify your code against the autograder as many times as you would like before the submission due date without penalty.
Please keep in mind that any submission made **after the due date** will be considered late and will either be counted towards your alloted late days or penalized accordingly.
(#) Attribution
This homework assignment was adapted from Peter Bui's [Python scripting assignment](https://www3.nd.edu/~pbui/teaching/cse.20289.sp20/homework05.html), which is licensed under a [Creative Commons Attribution 4.0 International License](https://creativecommons.org/licenses/by/4.0/).