


Next: Document-keyword correspondence
Up: Algorithm
Previous: How to extract document
Clustering based on similarity information in 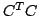 can be though of as
the following bipartite graph coclustering.
This concept has been explored in the document-keyword
analysis by Dhillon [4] and in bioinformatics by Kluger et al.
[8].
The document and keywords represent the two sets
of nodes in the bipartite graph,
and the co-occurring documents and keywords are connected by graph edges.
The graph has an edge weight matrix
can be though of as
the following bipartite graph coclustering.
This concept has been explored in the document-keyword
analysis by Dhillon [4] and in bioinformatics by Kluger et al.
[8].
The document and keywords represent the two sets
of nodes in the bipartite graph,
and the co-occurring documents and keywords are connected by graph edges.
The graph has an edge weight matrix
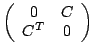 . These methods are based on finding the normalized cut in this graph.
Intuitively, this is the right thing to do, we want to select a set
of keyword for grouping a particular set of documents. Furthermore,
this grouping gives the correspondence between the informative keywords
and relevant documents.
However, graphcuts on bipartite graphs amounts to separate
clustering on documents and on keywords, given
by the fact that
and
. These methods are based on finding the normalized cut in this graph.
Intuitively, this is the right thing to do, we want to select a set
of keyword for grouping a particular set of documents. Furthermore,
this grouping gives the correspondence between the informative keywords
and relevant documents.
However, graphcuts on bipartite graphs amounts to separate
clustering on documents and on keywords, given
by the fact that
and
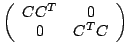 have the same eigenvectors.
Thus, finding the optimal partition on the bipartite graph contradicts the concepts of coclustering and simply results in clustering
the documents on the information given by .
have the same eigenvectors.
Thus, finding the optimal partition on the bipartite graph contradicts the concepts of coclustering and simply results in clustering
the documents on the information given by .
Next: Document-keyword correspondence
Up: Algorithm
Previous: How to extract document
Mirko Visontai
2004-05-13