CIS 120: SpellChecker
All modern word processors, along with increasingly many other programs, have a built in spell check function that allows even the worst typist some level of efficiency. To complete this homework you will be coding a rudimentary spell check program based on a dictionary and list of corrections for misspelled words.

A few notes before we begin:
In order to do well on this assignment, you must read the Javadocs for each class to be written! When completing each task below, first read the associated Javadoc so you know exactly what behavior the class should provide. The online tester will verify that you read and wrote your code to match the specification listed in the Javadocs. You will want to have the Javadocs open while you're coding.
For this project, you have only three free submissions. Subsequent submissions will cost you 5 points.
This means you won't be able to use the online testers to find your bugs! Writing your own tests will be critical to doing well.
File, class, and method names must be exactly as described in the Javadocs. (You may, of course, add your own helper variables and methods.)
The files for this assignment are at: hw08.zip. Setup instructions:
- In Eclipse, go to File > New > Project and choose Java Project. Hit Next.
- Use "HW08_SpellChecker" as the project name. Under Project layout, check the option for "Create separate folders for sources and class files." Hit Next.
- Click on the "Libraries" tab, and then "Add Library". Choose JUnit and then JUnit 4. Press Finish.
- Press Finish again to close the wizard.
- Right click on the src subdirectory in the new project SpellChecker in the Package Explorer, and select "Import".
- Choose File System, and in the "From directory" field, navigate to the folder where you unzipped the files.
- Check off all of the unzipped files (.java and .txt), and then hit Finish. The files should now be added! You can view them by expanding the "(default package)" entry in the Package Explorer.
- Move all of the .txt files up to the root of the project directory.
-
There is a challenge problem (worth no credit): see the
Levenshteinclass in the Javadocs.
Recall: I/O and Collections
This homework is designed for you to gain practice with Java I/O (see java.io) and the Java Collections Framework (see java.util). The I/O package is very large with lots of different classes to choose from -- we recommend taking a look at the following interfaces and classes:
| Input |
|---|
|
| Output |
|
| Collections |
*Scanner is technically in java.util (not java.io) because it implements the Iterable interface.
Step 0: A High Level Look
In order to create our spellchecker, we will create the following classes:
-
TokenScanner- parses files and break them up into token (words and nonwords) -
Dictionary- parses a text file and creates a list of words in the dictionary -
FileCorrectorand SwapCorrector- passed in an incorrect word and suggests possible corrections from a dictionary. -
SpellChecker- links the TokenScanner, Dictionary and Corrector in order to interactively spellcheck a document.
In addition to the provided files described above, we also provide several test classes (DictionaryTest, TokenScannerTest, etc.) and sample text files to run your code with.
This diagram depicts how these files interact: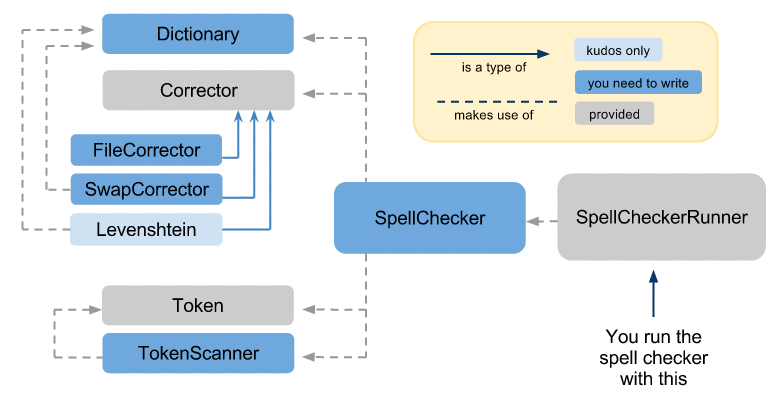
Step 1: Breaking Files into Tokens
File to submit: TokenScanner.java and
MyTests.java for test cases
Like the Histogram demo from lecture, we will first start with a
helper class for reading words in a file.
The purpose of this class, which implements the Iterator<String> interface, is to read the input file and split it up into
strings, called
tokens.
There are two sorts of tokens: words and non-words. Word tokens only contain word characters. Nonwords do not contain any word characters. (A word character is either a letter (see Character.isLetter) or an apostrophe.) Given an input stream of characters, the TokenScanner should alternate between producing words and nonword tokens from the input.
| File Contents | Expected Tokens |
|---|---|
| They aren't brown, are they? | "They" " " "aren't" " " "brown" ", " "are" " " "they" "?" |
|
It's time 2 e-mail! |
"It's" " " "time" "\n2 " "e" "-" "mail" "!" |
A few things worth pointing out:
Dark gold tokens are word tokens, green tokens are non-word tokens. Notice how we always alternate between the two types of tokens.
The newline character ("\n") should not be skipped. Note that some operating systems may produce two characters to indicate newlines ("\r\n"). If these characters are present in the input, then they should be part of some (nonword) token.
The assumption we made about word characters (being only letters and apostrophes) isn't perfect: notice how we split apart the word "e-mail". However, it's a reasonable simplification and our SpellChecker will still work for the majority a document's text.
The class TokenScanner, because it implements the Iterator<String>, must provide the following (be sure to brush up on the javadocs):
-
hasNext()- Tells the client whether any more tokens remain in the file -
next()- Returns the next token as aString -
remove()- We won't implement this functionality, so your remove method can just contain:throw new UnsupportedOperationException();
Read the TokenScanner javadocs, and then open up TokenScannerTest.java and examine the provided test case.
Before you start your implementation, you should add more unit tests for this class to
MyTests.java to
exercise all of the intended behavior.
What tests should you add? Think about various situations that could occur for
your token scanner.
- The input is empty.
- The input contains a single word token.
- The input contains a single non-word token.
- The input contains both word tokens and nonword tokens, and ends with a word.
- The input contains both word tokens and nonword tokens, and ends with a nonword.
TokenScanner, and you want to find out about such bugs before
you continue to the remainder of the assignment. 1.2 TokenScanner.java
Next, implementTokenScanner so that it
passes your tests. Note that the constructor is allowed to throw
IOExceptions, but the next method should catch them and throw
NoSuchElementException so that it conforms to the Iterator
signature.
TIP: You may want to look at the WordScanner written in class for an example of how to approach this problem.
Tip: If you followed the setup instructions, your files should compile and you should be able to run your JUnit tests. If this isn't working, make sure that your text input files are in the root project folder, not in the src/ folder.
Also: Always remember to close your input streams in your test cases! If you find a test is not running, you may need to delete the file or exit the Java process in order to manually close the stream.
Step 2: Building a Dictionary
File to submit: Dictionary.java and MyTests.java for
test cases
Before we can actually program the spellchecker we need a class that reads in words from the dictionary, stores them in memory, and provides efficient access to them. In this case, a dictionary is just a list of 'legal' words, and we do not store any definitions.
Begin by reading the Javadoc
for the Dictionary class, to understand what it does.
2.1 Add Test Cases
Once you understand what the Dictionary class does, open DictionaryTest.java.
We only provide a few test cases in this file. Passing the given tests
doesn't mean your code works for all input! Using the given test
cases as a template, add test cases to MyTests.java for the following situations. By a
test case, we mean that you should make the certain scenario happen,
and check that the response matches what should happen, as
outlined in the Javadocs. Use methods like assertEquals,
assertTrue, assertFalse to verify the correct behavior (Recall
that documentation for the assert methods can be found
here).
Each bullet below should be its own test method:
- You check for a word that is in the dictionary.
- You check for a word that is NOT in the dictionary.
- You ask for the number of words in the dictionary. (Does it return the right thing? Hardcode in the answer you expect based on your test dictionary file.)
- You check that the empty string "" is not a word.
- You check for a word that is all uppercase, but the word appears in the dictionary file in lowercase.
- The dictionary file contains a blank line in the middle. (Remember: You can always make new .txt files to help write test cases.)
- The dictionary file has words in mixed case (e.g. eLePHant) and you check if one of those words is in the dictionary.
- The dictionary file has words with whitespace around them, and you check if one of those words is in the dictionary.
- The same word appears twice in the dictionary file, and you ask for the number of words in the dictionary.
Are there any other test situations or corner cases which may occur? We've left out some scenarios from the list above. You should write additional test cases for any other situations you think of.
TIP: Don't forget about null!
2.2 Dictionary.java
Once you feel confident that your tests cover all aspects of the expected behavior, open up Dictionary.java. We have provided template methods, and you will have to fill in the implementation.
You should run your tests, find what fails, and correct the code until your test cases pass.
Using the Right Data Structure
Choosing the right data structure to store the dictionary is
crucial. If the dictionary contains 1000000 words, you don't want to
be re-reading and searching through all of those words each
time isWord() is called. The implementation of
the data structure is also important - different ways of storing data
make different operations efficient. Ask yourself:
- Is a List the right data structure to store the
dictionary? What benefits does a list have over a set or map? Are
these necessary for a Dictionary?
- The
ArrayListclass implements lists using resizeable arrays. - The
LinkedListclass implements lists using linked lists of nodes.
- The
- Is a Set the right data structure to store the dictionary? How does the set differ from a list or a map? Do the properties of a Set fit the description of a Dictionary?
- Is a Map the right data structure to store the
dictionary? If so, what kind of map is it? (e.g. String to String,
String to Integer, etc.)
- The
TreeMapclass implements maps by storing keys in a sorted binary tree.
- The
It is critical that your Dictionary works properly before moving on! Make sure that the method signatures match those in the Javadoc exactly.
Step 3: Adding Correctors
Files to submit:
FileCorrector.java,
SwapCorrector.java
and MyTests.java for
test cases.
Suppose while reading a file we encounter a word doesn't that is not in a dictionary. How could we fix it?
Corrector is an abstract class where the getCorrections method is abstract. An abstract class has some similarities to an interface; the biggest difference is that abstract classes can have some implemented methods. Here matchCase is implemented, but getCorrections is not. Any subclass of Corrector must implement getCorrections, and thus is able to provide corrections for a given misspelled word. We will implement two different kinds of Correctors:
FileCorrector- uses a reference text file containing common misspellings to provide suggestions for a misspelled word.SwapCorrector- uses a Dictionary, and suggests any words from it that are a single "swap" from the given incorrect word. For example, it might suggest "this" if the incorrect word was "thsi". A swap is two adjacent letters that are reversed in their positions.
3.1 Adding Tests, Implementing FileCorrector.java
Read the documentation for FileCorrector, and then add the following test cases (plus your own) to MyTests.java:
- The corrections file has extra whitespace around a line, or around the comma. You can (and should) create your own new .txt files to help write these test cases!
- We ask for a word that has no corrections.
- We ask for a word that has multiple corrections.
- The input file has some lines with mixed case (e.g. word,CoRRecTioN or WORD,correction) and you ask for that word's corrections.
- We ask for a fully uppercase word that has corrections. What case should the results have?
- We ask for that same word, but now lowercase, that has corrections. What case should the results have?
The list above isn't comprehensive, so make sure to add your own additional test cases for any other behavior described in the Javadocs.
When you are finished adding test cases, write
the FileCorrector class and ensure it passes your
tests. Think carefully about which data structure is the best suited
for storing the data read from the file.
TIP: You may want to look at
the indexOf and substring methods
of String
to help you extract the incorrect and correct words from any given
line.
TIP: This tip applies to writing
both FileCorrector and SwapCorrector.
The getCorrections method requires that the suggested corrections have the same case as the given incorrect word. Thus, if "pease" was the incorrect word, we should suggest the set {"peas", "peace"}, but if either "PEASE" or "Pease" or "PeAsE" is the incorrect word, we should suggest back the set {"Peas", "Peace"}. (Only first letter capitalization is relevant.)
To help with the capitalization correction, the abstract class Corrector has a helper method matchCase that FileCorrector and SwapCorrector can both use. Notice how putting this in the parent class allows us to avoid duplicating code in the two subclasses.
3.2 Adding Tests, Implementing SwapCorrector.java
Repeat the above procedure for implementing SwapCorrector: look at the Javadocs and add necessary test cases, and then implement the class itself.
Here are some suggested test cases, but we've left out quite a few:
- The provided dictionary is null.
- You ask for corrections for a word that itself is already in the dictionary.
- You ask for corrections for a word that is mixed case.
TIP: Remember that you can create your own dictionary files to help with testing! For example, if you make a test case that asks for corrections for the incorrect word "abcd", you may want to create your own dictionary file that contains "bacd", "acbd", etc and ensure your method doesn't miss any of the swaps!
All IOExceptions that may result from the execution of the Correctors do not need to be caught.
Read the Javadocs closely for the Correctors and make sure to test all of the possible edge cases!
Step 4: Creating the SpellChecker
File to submit: SpellChecker.java and
MyTests.java for test cases
The end is near!
We need to put all of our classes together. A SpellChecker object takes in a Corrector and a Dictionary when constructed. When checkDocument is called, it should read tokens from the input document, spell-check any incorrect words, and write the output to a file using a Writer
object.
Most of SpellChecker has already been written, except for the method that processes the document and does the checking.
Sample Output/Interaction
Click here to see a sample of the
output and interaction functionality we expect to see when running
the finished program. You should closely emulate this output in
your SpellChecker class.
4.1 checkDocument in SpellChecker.java
Complete the checkDocument method in SpellChecker.java so it matches the functionality above. Bear in mind the following:
Read the Javadocs for the SpellChecker class first! :)
-
Non-word tokens should be copied directly from the input document into the newly corrected file. Only word tokens should be checked for spelling and (possibly) replaced.
-
If the user chooses option 1 ("replace with another word"), they can only enter single word replacements. This is taken care of for you by the provided
getNextStringhelper method. You should use the submitted word verbatim; no need to correct the word case. -
If a word isn't in the dictionary, then we want to check if our Corrector has any suggestions for it. If more than one correction is available, then the possible corrections should be presented to the user in alphabetical order.
TIP: To alphabetically sort a string set, use the following:
// Suppose setOfCorrections is the Set<String> you got from a Corrector. List<String> sortedOptions = new LinkedList<String>(setOfCorrections); Collections.sort(sortedOptions); // sortedOptions is a sorted list, e.g. {"alpha", "beta"} // You can now use the List as you wish; see the List Javadocs. String first = sortedOptions.get(0); // "alpha" String second = sortedOptions.get(1); // "beta" IOExceptions don't need to be caught, but you should handle invalid user input appropriately.
For example, if you give a user four options and they enter an invalid selection (such as 12 or "oaijeoijwef"), you should notify them and prompt for a selection again.
TIP: We provide code to help you with this: see
getNextIntandgetNextStringin the partial SpellChecker implementation provided.Your user display and options should match the sample output above. For example, do NOT number your options 1,2,3 instead of 0,1,2. We will test your code automatically with a file of user inputs.
Testing: Command Line or Running in Eclipse
The sample test case in SpellCheckerTest uses a file as the "user" input so it can run automatically.
If you are familiar with the command line, you can run
SpellCheckerRunner automatically. From the root directory of your
project in your workspace:
$ java -cp bin SpellCheckerRunner Gettysburg.txt Gettysburg-out.txt dictionary.txt mispellings.txt
Otherwise, you can run the SpellChecker manually in Eclipse. Here's how:
- Go to Run > Run Configurations.
- Right click on Java Application and choose "New".
- Under "Main class", you should put
SpellCheckerRunner. - Switch from the "Main" tab to the "Arguments" tab.
- Under "Program arguments:", you can put the inputs to the runner. For example:
- You can give this configuration a name in the "Name:" bar at the top, so you can identify this from other runs.
- Hit "Apply" and "Run".
- The program will run in the "Console" tab, normally at the bottom below your code editors. (Your layout may be different.)
You can return to this configuration and change the arguments to run it with different input files, or to switch between different types of Correctors.
To edit a configuration, in the Run Configurations panel, select the named configuration under "Java Application" on the left side.
To re-run a configuration (after it has been set up), you can choose the configuration (as if you were editing it) and hit "Run". Alternatively, if you have recently run it, you can click the little arrow next to the green button at the top of Eclipse:
TIP: When you run the SpellChecker through Eclipse, you will need to refresh the Eclipse package in order to see the newly created output file.
TIP: If you are encountering an infinite loop when using theFox.txt, pay attention to how your token scanner handles end of file characters.
Challenge Problem
If the drive to create the world's best spell checker has consumed you, you can implement a third type of corrector, Levenshtein.java. This kind of Corrector proposes words that are a Levenshtein distance of 1 away from the incorrect word. This is kudos-only and worth no points.

Submitting and Grade Breakdown
As usual, you will be submitting on the submissions page. We're back to the straightforward submissions of individual .java files. This is listed on the page, but the files you will be submitting are Dictionary.java, FileCorrector.java, SwapCorrector.java, TokenScanner.java, SpellChecker.java, and Levenshtein.java (even if you didn't do the challenge problem). The grade breakdown among the problems is as follows:- 1: TokenScanner - 20%
- 2: Dictionary - 18%
- 3.1: FileCorrector - 18%
- 3.2: SwapCorrector - 16%
- 4: SpellChecker - 18%
- 5: Style - 5%, manually graded
- 6: Testing - 5%, manually graded
- Kudos: Levenshtein - 0%